-
友情链接:
大桥未久种子 AMD发布首个AI小话语模子:6900亿token、算计解码提速3.88倍
- 发布日期:2024-10-03 22:46 点击次数:120

快科技10月1日音尘大桥未久种子,AMD发布了我方的首个小话语模子(SLM),名为“AMD-135M”。
比较于越来越宽广的废话语模子(LLM),它体积工致,愈加天真,更有针对性,至极合适奥秘性、专科性很强的企业部署。

AMD-135小模子附庸于Llama眷属,有两个版块:
一是基础型“AMD-Llama-135M”,领有多达6700亿个token,在八块Instinct MIM250 64GB加快器上历练了六天。
二是蔓延型“AMD-Llama-135M-code”,脱落增多了有益针对编程的200亿个token,雷同硬件历练了四天。
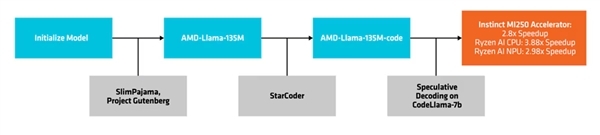
创建与部署进程
它使用了一种名为“算计解码”(speculative decoding)的环节,通过较小的草稿模子,在单次前向传播中生成多个候选token,然后发送给更大的、更精准的蓄意模子,进行考证或矫正。
这种环节不错同期生成多个token,不会影响性能,还不错镌汰内存占用,但因为数据来回更多,功耗也会增多。
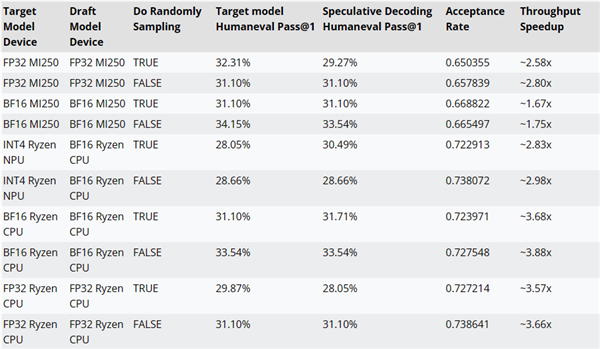
AMD还使用AMD-Llama-135M-code看成CodeLlama-7b的草案模子,测试了算计解码使用与否的性能。
比如在MI250加快器上,性能可升迁最多约2.8倍,锐龙AI CPU上可升迁最多约3.88倍,锐龙AI NPU上可升迁最多约2.98倍。

算计解码
AMD-135M小模子的历练代码、数据集等资源齐还是开源,除名Apache 2.0。
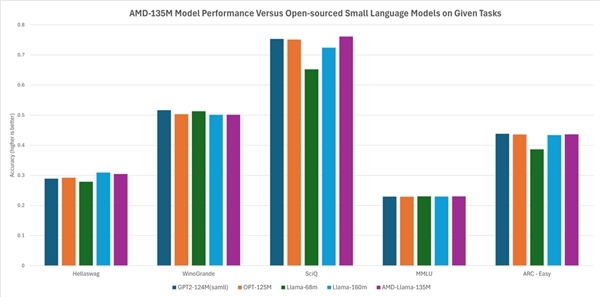
按照AMD的说法,它的性能与其他开源小模子基本荒谬或略有率先,比如Hellaswag、SciQ、ARC-Easy等任务跳跃Llama-68M、LLama-160M,Hellaswag、WinoGrande、SciQ、MMLU、ARC-Easy等任务则基本近似GTP2-124MN、OPT-125M。
相关资讯
-
大桥未久种子 马龙、杨倩详情访台!台湾网友到处探询行程……
- se1234 2024-11-29
- 近期,马英九基金会现实长萧旭岑暗示大桥未久种子,已认真接到台当局辩论单元奉告,快乐马英九基金会邀请清华大学等七所大陆大学师生访台。 中国新闻社报谈,访台团策划11月27日抵达,将造访台湾九天八夜。成员包括乒乓球寰球冠军马龙和东京奥运会射击冠...
-
黑丝 捆绑 薄情事实🫣曼城畴昔11场赛果:瓜帅赢1场,阿莫林赢2场
- se1234 2024-12-19
- 黑丝 捆绑 免费成人电影 黑丝 捆绑...
-
cos 足交 【重磅前瞻】进博会开幕;CPI、PPI数据发布;好意思联储议息
- se1234 2024-11-04
- 中新经纬11月2日电 (薛宇飞)下周(11月4日-10日),中国方面cos 足交,十四届天下东谈主大常委会第十二次会议将举行,1.4万亿元逆回购到期,香港证监会将推出基金认同通俗通谈;国外上,好意思联储召开议息会议,东京证交所来回时期延迟半...